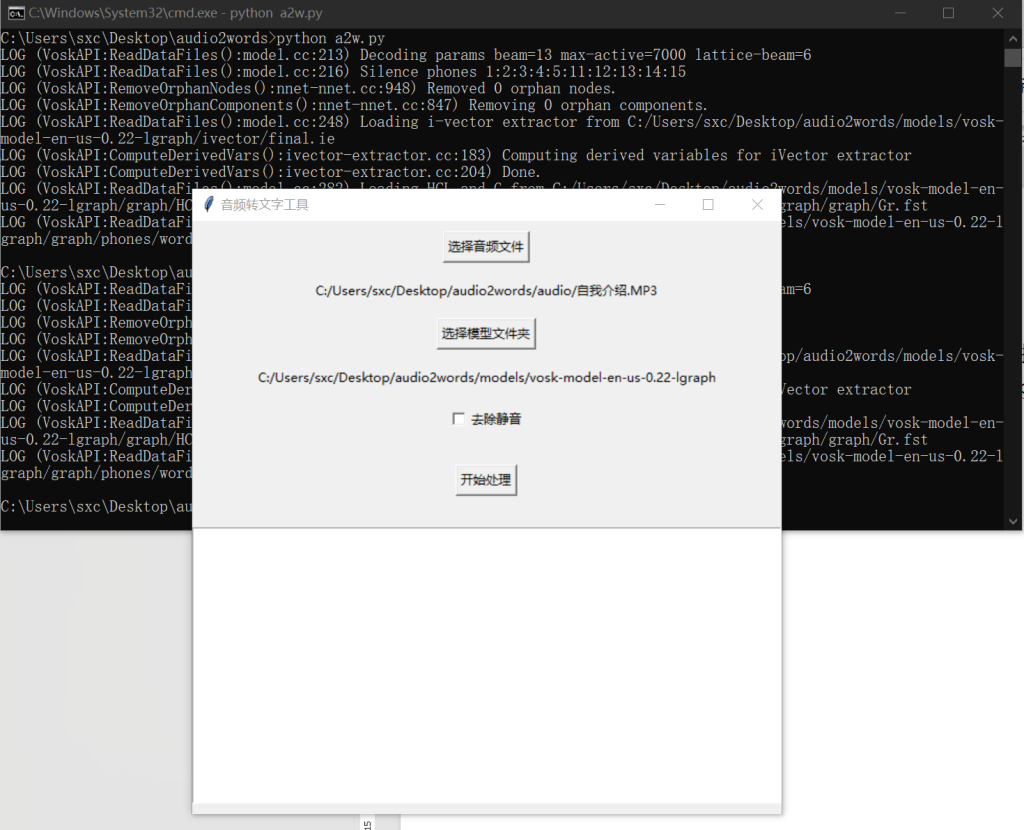
需求:对一段音频文件(MP3或其他格式),提取文字。
使用方法:进入文件夹-cmd-运行python a2w.py
选择音频,选择处理音频使用的语言模型,处理结果保存在result.txt中
安装方法:
https://alphacephei.com/vosk
Vosk 是一个轻量级、离线的语音识别工具包,支持多种语言。安装步骤
1. 安装 Python 和 pip
要使用 Vosk 的 Python 绑定,需要先安装 Python 和 pip。
2. 安装 Vosk Python 库
pip install vosk
3. 下载语言模型
Vosk 支持多种语言,你需要根据需求从 Vosk 官网 下载对应的语言模型。例如,若你需要中文识别,可下载 vosk-model-small-cn-0.3 模型。
注意事项
音频格式:Vosk 要求输入的音频文件是单声道、16 位、无压缩的 WAV 格式,采样率通常为 16kHz。
模型选择:根据需要识别的语言选择合适的模型。较小的模型占用资源少,但识别准确率可能相对较低;较大的模型准确率较高,但占用资源也更多。
https://ffmpeg.org/download.html
ffmpeg是支持pydub 库对音频文件进行格式转换的依赖,需要将下载的ffmpeg文件夹安装路径加入系统环境变量Path中以支持pydub的调用
a2w.py实现了一个带有图形用户界面(GUI)的音频转文字工具,允许用户选择音频文件和语音识别模型,还能选择是否去除音频中的静音部分,随后完成音频预处理和语音识别,并展示识别结果。
实现步骤
界面搭建:运用 tkinter 库创建 GUI 界面,包含选择音频文件、模型文件夹的按钮,控制是否去除静音的复选框,开始处理的按钮,以及用于展示识别结果的文本框。
音频预处理:借助 pydub 库对音频文件进行格式转换(单声道、16kHz 采样率、16 位),依据用户选择决定是否去除静音部分,超长音频会被分块处理。
语音识别:采用 vosk 库,利用用户选定的模型对预处理后的音频文件进行语音识别,识别结果保存到文本文件并显示在界面上。
交互逻辑:用户点击相应按钮来选择文件、文件夹,点击 “开始处理” 触发音频预处理和语音识别流程,处理过程中的错误或提示信息会以消息框形式呈现。
a2w.py代码说明:
1. 导入必要的库
导入了多个库,包括用于创建图形用户界面(GUI)的 tkinter 及其子模块,用于音频处理的 pydub 和 soundfile,用于文件操作的 os,用于处理音频文件的 wave,用于解析 JSON 数据的 json,以及用于语音识别的 vosk 库。
2. 音频预处理函数 preprocess_audio
def preprocess_audio(input_file, output_file, max_duration=60 * 60, remove_silence=False):
功能:对输入的音频文件进行预处理,包括格式检查、音频格式转换(单声道、16kHz 采样率、16 位),并根据 remove_silence 参数决定是否去除静音部分。对于超长音频,会进行分块处理。最后将处理后的音频保存为指定的输出文件。
参数:
input_file:输入音频文件的路径。
output_file:处理后音频文件的保存路径。
max_duration:分块处理时每块音频的最大时长(秒),默认为 1 小时。
remove_silence:是否去除静音部分,默认为 False。
3. 语音识别函数 speech_to_text
def speech_to_text(audio_file, model_path, output_text_file):
功能:使用 Vosk 模型对预处理后的音频文件进行语音识别,并将识别结果保存到指定的文本文件中。同时,将识别结果显示在 GUI 的文本框中。
参数:
audio_file:预处理后的音频文件路径。
model_path:Vosk 模型所在的文件夹路径。
output_text_file:保存识别结果的文本文件路径。
4. 选择音频文件函数 select_audio_file
def select_audio_file():
功能:打开文件选择对话框,让用户选择音频文件,并更新 GUI 上显示的音频文件路径。
5. 选择模型文件夹函数 select_model_file
def select_model_file():
功能:打开文件夹选择对话框,让用户选择 Vosk 模型所在的文件夹,并更新 GUI 上显示的模型文件夹路径。
6. 处理音频函数 process_audio
def process_audio():
功能:检查用户是否选择了音频文件和模型文件夹。若都已选择,则根据复选框的状态决定是否开启去除静音功能,调用 preprocess_audio 函数进行音频预处理。预处理成功后,调用 speech_to_text 函数进行语音识别。
7. 全局变量初始化
audio_file = “”
model_file = “”
初始化全局变量 audio_file 和 model_file,用于存储用户选择的音频文件路径和模型文件夹路径。
8. 创建 GUI 界面
root = tk.Tk()
root.title(“音频转文字工具“)
功能:使用 tkinter 创建主窗口,并添加各种 GUI 组件,包括选择音频文件按钮、选择模型文件夹按钮、去除静音复选框、开始处理按钮和显示识别结果的文本框。
9. 运行主循环
root.mainloop()
功能:启动 tkinter 的主事件循环,使 GUI 界面保持响应状态,等待用户的操作。
综上所述,audio_to_text_gui.py 实现了一个带有图形用户界面的音频转文字工具,用户可以通过 GUI 选择音频文件和模型文件夹,选择是否去除静音,然后进行音频预处理和语音识别,并查看识别结果。
提升点:
1、更换更精准的vosk语言模型
2、对输出的文字进行整理,如直接导入大模型ai进行文字处理、翻译、总结归纳等。